





前回の問いから、今回の課題へ
前回の「読書」のエピソードでお伝えしたかったのは、地名の「読み」には、字面だけでは見えない土地の記憶が宿っているということでした。
ならば、地図上の地名すべてにその読みを載せれば、その記憶に触れやすくなるはずです。ところが、その「すべての地名にふりがなを振る」という一見シンプルな目標が、制作上の大きな問題を引き起こすことになりました。それは、現在、地図を作るのに使っているIllustratorというアプリケーションには、「ルビ」を振る機能がないからです。
少し脱線しますが、「ルビ」という言葉の説明をさせてください。出版の世界では、ふりがなのことを「ルビ」と呼びます。本書では、掲載するすべての地名にルビを付す「総ルビ」、しかも漢字一文字ごとに読みを対応させる「モノルビ」を採用しています。従来の地図の多くは、難読地名にだけルビを振る「パラルビ」でした。それに対して本書は、「すべての地名に」「漢字一文字ずつ」ルビを振るという、これまでにない仕様になっています。

Illustratorに「ルビ機能」がないという話に戻ります。ネットで検索をすると、さまざまな解決方法が見つかります。ただし、そのほとんどが、ふりがなを1つずつ手作業で振るというものでした。
今回の地図に掲載されている地名数は、比較的少なめに抑えていますが、それでも日本全国で見れば、地名は3万を優に超えます。
仮に、1つの地名にルビを振るのに5分かかるとします。
- 1時間で12件
- 1日(8時間)で約100件
このペースで3万件にルビを振ると、300日かかります。しかもこれは、単にIllustratorでルビを振るだけの話です。実際には、
- ルビ振りのための辞書構築
- 読みの確認
- 文字の重なりの調整
といった作業も必要になります。全体で300日の数倍はかかりそうです。こうなると、手作業でルビ振りをやるという選択は、ほとんど現実的ではありませんでした。
解決の鍵はスクリプトだった
そこで必要になったのが、ルビ振りの自動化です。調査の中で見つけたのが、「illustrator-ruby」というスクリプト(いなにわうどん氏が開発)でした。このスクリプトはオープンソースで公開されており、日本語組版の仕様にも配慮された、信頼性の高いルビ処理が可能です。これをベースに、本企画に合わせた拡張を行いました。
同一表記で異なる読み
特に重要だったのが、「同じ漢字でも読みが異なる地名」に対応することです。日本語の地名の難しさは、ここにあります。
- 上田:うえだ/うえた/かみだ/じょうでん など
- 神戸:こうべ/ごうど/かんべ など
のように、同じ漢字表記で読みが異なる地名が多数存在します。ところが、illustrator-rubyのルビ処理は漢字表記をキーにして行われます。本書は、「読み」を重視する地図帳です。なんとしても、この複数読みに対応しなければなりません。
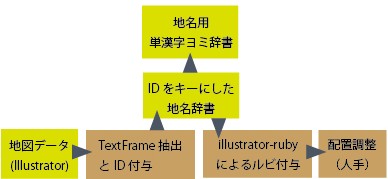
そこで、すべての地名オブジェクトにIDを付与し、そのIDをキーに読みを割り当てる仕組みを導入しました。これにより、同一表記で異なる読みがあっても、正確にルビを振ることが可能になりました。
地名専用の読み辞書
本書のふりがなの振り方は、先述のように「モノルビ」という方式をとっています。この方式に対応するため、地名専用の漢字単位の読み辞書も整備しました。
漢字と読みの対応関係を整理し、スクリプトと組み合わせることで、大量の読みに対するモノルビ処理を効率的に行えるようにしています。ただし、地名に出現する漢字の読みが辞書に登録されていないとモノルビ化処理に失敗します。その場合には、一つひとつ辞書に漢字の読みを手で追加します。地道な仕事です。
文字配置の「パズル化」
しかし、問題はこれで終わりではありません。ルビを付すことで、文字量は一気に増えます。とくに地名が密集する地域では、文字同士の干渉が避けられません。考えてみれば、地名が密集するということは、その土地に人々の記憶が密集しているということでもあります。読みを省略せず、すべてを載せることにこだわった結果として生まれた「パズル」でした。
- ある地名を少し動かすと、…
- 別の地名とぶつかり、…
- それを調整するとさらに別の箇所に影響する
というパズル化が頻繁に起こります。一箇所を直すと、別の箇所が崩れる――そんな調整の連続です。この部分は、現在の技術では自動化が難しく、最終的には人の目でバランスを見ながら調整するしかありません。
技術と人手のあいだで
以上のように、総ルビ地図の実現は、
- スクリプトによる自動化
- 辞書による処理基盤
- 人の手による最終調整
この3つの積み重ねによって支えられています。
その結果として、地名を「音」として読むことができる、これまでにない地図が生まれました。第1回で触れた「地名は音である」という感覚を、実際に体験できる地図の登場です。
